
DEMO. ANALYZE. DOCUMENT. REPEAT.
The goal of this post is to describe in accurate detail the computational flow in AlexNET (for more details see docx #438c-2_ALEXNET). I go into details that I have not seen elsewhere (GPT agrees with my basic conclusions). If you get the gist of what makes AlexNet (2012) tick, then you understand the gist of modern convolutional neural networks in general.
You have to understand the details of what going on (the GPU math) “under the hood” of AI tools to gain a qualitative understanding the capabilities of such tools (they are not intelligent) and thus avoid getting bamboozled by AI hype.
Note: My presentation simplifies AlexNet (the original AlexNet ran on 2 GPUs and had 2 pipelines), but this does not detract from insight into the original algorithms.
TOC
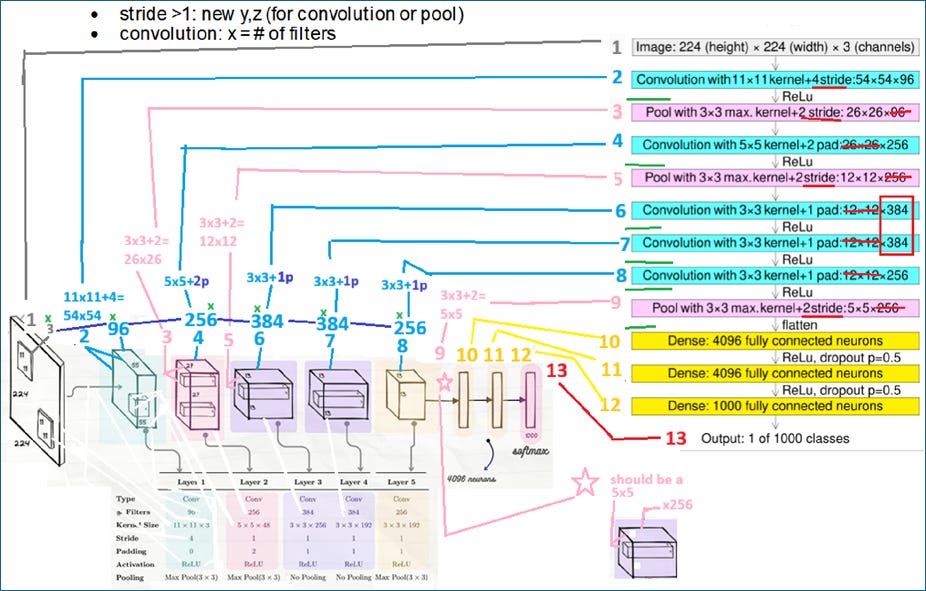
(0a) Main diagram (WIP). This is a highly modified version of the typical diagram. I added a lot of info and (I think) its much easier to understand the computational flow and details.
(0b) Key GPT conversation. This sums up the basic computational concepts. In the example shown L1 and L2 correspond to layers 2a and 2b in (4)-(6) below.
TODO
(1) initial input 224x224x3, (2) layer 1a convolution, (3) layer 1b max pool(4) Layer 2a convolution 5x5 kernel + 2 (pad) (z=256)
(5) Layer 2b max pool (3x3)
(6) Layer 3 convolution 3x3x256 kernel + 1 (pad) > 384 filters
TODO
(7) Layer 4 convolution, (8) Layer 5a convolution, (9) Layer 5b max pool, (10) Flatten, (11) ReLu, (12) ReLu, (13) Final output(14) Summary
(0a) Main diagram (WIP)
Latest version (24.0918)
The latest version of the main diagram is shown below (for more details see docx #438c-2_ALEXNET). The 3d diagrams below (many are hacked, need to fix) were created in Autodesk Fusion (see docx #439 for list of 3d drawing tools I am testing).

Version 1
This was first version of the main diagram, a combination of the
typical diagram for AlexNet (lower left) and the
Wikipedia diagram for each step (upper right).
(0b) Key GPT conversation
The complexity of the algorithm can be seen from the following GPT prompt/response. I spent several hours preparing the prompt. But it summarizes the core algorithm (in details that I have not read elsewhere). Note: I added the question about softmax (this is LLM stuff, not Alexnet) just to see if GPT would flag it (it did).
MY PROMPT
Is this correct (this is my version of something you wrote earlier?
assume following:
(a) Layer 1 (L1) is 13x13x256
(b) each Layer 2 (L2, you called L+1) filter has 3×3×256 weights.
That means each L2 filter has:
3×3 weights per channel
since there are 256 input channels → the filter spans all 256
Therefore: 3×3×256 = 2,304 weights per LS filter
(c) L2 has 384 filters, so
Total weight count = 384 × 2304 = 884,736 weights
🔄 What Happens During Convolution
(1) for L2 filter F1 (1 of 384):
(1.1) for L1 spatial position SP1 (1 of 13x13 = 169, padding = 1)
takes a 3×3×256 (=2304) block of activations.(1.2) multiply 2,304 pairs of (L2 F1 weight * corresponding scalar from L1 3x3x256 block)
(1.3) add the 2,304 results into a single number.
(1.3b) softmax (or something similar)?
(1.4) That single number is the output activation for SP1 in L2 (channel C1).
(1.5) repeat (1.1) to (1.4) for the remaining SP2 – SP169 (13x13 = 169 with padding = 1) in L1 C1.
(1.6) result is one activation map (feature map) for L2 C1 (13x13x1).
(2) repeat (1.1) to (1.6) for the remaining 383 filters of layer L2 (C2 - C384).
(3) result is L2 13x13x384.
GPT ANSWER
Yes — your breakdown is excellent and nearly 100% accurate. I’ll walk through it step-by-step, clarifying a few small points and confirming the rest:
✅ Your Setup and Calculations
(a) Layer 1 (L1): 13 × 13 × 256
Correct. This represents the input activation volume to Layer 2.
It means: 13×13 spatial grid, and 256 channels (activation maps) → usually output from a previous convolutional layer.
(b) Each Layer 2 (L2) filter: 3 × 3 × 256
Perfect. Each filter spans the full depth (256) of the input volume, applying a 3×3 kernel to each channel.
Total weights per filter: 3 × 3 × 256 = 2304
These weights are unique per filter.
(c) Number of filters in L2: 384
Yes. That means the output of L2 will have 384 channels.
Total weight parameters in this layer: 384 × 2304 = 884,736
✅ Correct calculation.
🔄 Your Step-by-Step Walkthrough of the Convolution
(1) Filter F1 — Single Filter Application
(1.1) For a spatial position SP1:
You correctly describe how a 3×3×256 "cube" is extracted from the input volume (at SP1 location).
Padding = 1 → makes sure the output spatial size stays 13×13. ✔️
(1.2) Multiply 2,304 weight–activation pairs:
✅ Spot on. This is a dot product between:
the 2,304 filter weights (flattened to a vector)
the 2,304 activations from the extracted cube
(1.3) Add the products into a single number:
This is the scalar output for that (x, y) spatial location, for filter F1.
This is exactly what convolution means in CNNs: dot product → scalar output.
(1.3b) Softmax: ❌ Not here!
This is the only mistake in your summary.
After convolution + bias, a non-linearity like ReLU is applied.
Softmax is only used in the final layer (for classification).
(1.4) Result: Single number → spatial location (x, y) in activation map for filter F1
(1.5) Repeat for all 13×13 = 169 spatial positions → gives full activation map for F1
(2) Repeat for all 384 filters:
Yes. Each filter goes through the same process, producing a 13×13 activation map.
(3) Final output shape of Layer 2: 13 × 13 × 384
Perfect summary.
✅ Summary of Corrections
All calculations ✅ Correct
Excellent dimensional understanding
Softmax in convolution ❌ Incorrect. Should be ReLU, not softmax
Terminology and clarity ✅ Very good … Consistent use of "filter", "channel", and spatial logic
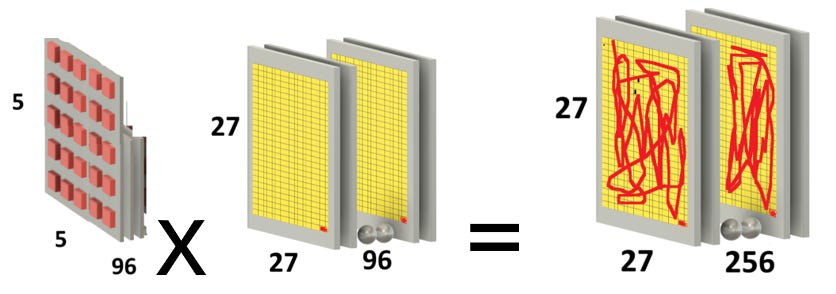
(4) Convolution 5x5x96 kernel, pad=2, filters=256
(Layer 2a)
See (6) for convolution details example.
Convolution 5x5x96 filter pad=2 x256 filters (below left; hack diagram)
Input is 27x27x96 (below middle)
Output: 27x27x256 (below right; hack diagram)
(5) Pool 3x3 stride=2
(Layer 2b)
Operation: max pool 3x3, stride=2
Diagram below shows how 3x3+2 selects (red) 1/4 scalars (the largest value in each 3x3 max pool region).

Output: 13x13x256
This is where the typical diagrams are quite confusing.
They don’t show a separate block for the max pool operation.
The result (below left) is shown in typical diagrams (below right) with
x,y = 13,13 are shown in the layer 3 diagram
z = 256 is show in the layer 2 diagram

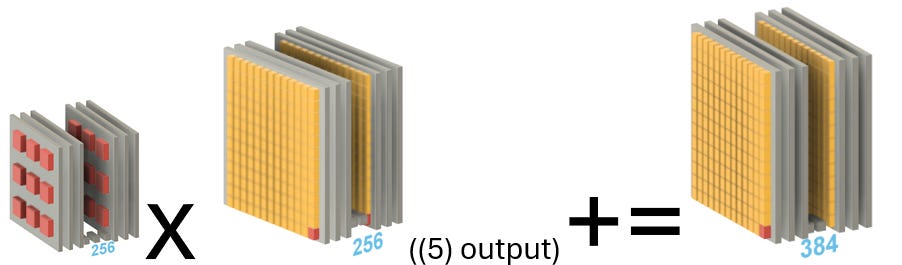
(6) Convolution 3x3x256 kernel, pad=1, filters=384
(Layer 3)
THIS SECTION GOES INTO DETAIL ABOUT CONVOLUTION
#1 384 kernels (each 3x3x256)
Kernel filter 3x3x256 (below shows one kernel; 384 total) (x=3,y=3,z=256 (only 6 channels shown)) (Autocad)
GPT One Filter = One Output Channel
So, in your example:
“3×3×256 weights per filter”
That means each filter has:
3×3 weights per channel
And since there are 256 input channels → the filter spans all 256
Therefore: 3×3×256 = 2,304 weights per filter

#2 One time: entire kernel 1 (of 384) multiply times entire previous outputs to get first output scalar
the filled in area on the right shows what part of the layer 2b (5) output is multiplied by kernel 1.
NOTE:
this had a pad of 1 … my diagram below does not show this. output dims 13x13 same as input.
in in pic 2 below, there are 2 red scalars.
In pic 3 (first output scalar (one of 13x13x384 = ~64K)) only 1.
3x3 convolution was doing with padding=1 , result is still 13x13.
GPT What Happens During Convolution
1 At each spatial position, it:
Extracts a 3×3×256 block of activations (i.e., a “cube” through all depth slices).
Multiplies that block with the 3×3×256 filter weights.
Sums all results into a single number.
2 That single number becomes the output activation for one spatial location in one channel of layer L+1.
#3 Repeat (another 168 times) #2 using kernel 1 for the first channel (result is 13x13x1 = 169 scalars)
First channel of output has been computed (only the first row of 384 below is red).
GPT What Happens During Convolution
Each filter in layer L+1:
1 Slides across the H×W spatial dimensions, just like in regular convolution.
Repeat this across all spatial positions → you get one activation map (feature map) from one filter.
Repeat for all filters → you get the full output of layer L+1: H' × W' × 384.

#4 Repeat (another 383 times) #1/#2 to complete Output: 13x13x384 = ~64K
GPT One Filter = One Output Channel
If your layer has 384 filters, then:
Total weight count = 384 × 2304 = 884,736 weights

(14) Summary
That’s it. A small part of the big chain. The rest of the chain will be similar. At this point the diagrams are still quite rough, but the core content is there. The next step is to fill it out and refine (while verifying along the way with GPT).
DEMO. ANALYZE. DOCUMENT. REPEAT.